Despliegues resilientes y escalables para Hyperledger Fabric
Una vez hemos visto cómo funciona Hyperledger Fabric en el artículo anterior y hemos entendido qué función cumple cada uno de los elementos, vamos a dedicar este artículo a pensar sobre cómo hacer un despliegue resiliente y escalable
Fase 1: Un despliegue sencillo
Empecemos por lo más sencillo, para luego ir añadiendo más complejidad una vez superada la fase inicial.
Pensemos en un despliegue en la nube de cualquier operador de cloud computing (AWS, Google, Azure, IBM, etc) basado en máquinas virtuales. Esta fase 1 no trata de una infraestructura aconsejada para entornos en producción, pero sí será interesante estudiarla para que luego la hagamos crecer.
Nuestro despliegue sencillo tendrá estos elementos:
- Máquinas virtuales independientes para cada funcionalidad
- Reglas de firewall que permitan tráfico de entrada y salida de las redes virtuales
- Nombres DNS para que los servicios puedan llamarse unos a otros y sean alcanzables desde Internet.
Listado de máquinas virtuales:
- Servidor virtual para la autoridad certificadora, usaremos el software “fabric-ca-server” como herramienta de gestión de certificados e identidades
- Servidor virtual para un orderer, será el único del servicio de ordering
- Un solo servidor peer, que irá alojado también en su propio servidor virtual
Cada servidor tendrá su alojamiento local, sus propias CPUs y su memoria RAM dedicada. Todo muy clásico, como puede verse.
Networking
En cuanto a las reglas de firewall, todo va a depender de cómo vaya a funcionar nuestro sistema con el exterior. Si suponemos que el único contacto con el exterior serán los chaincodes que ejecute el peer, el puerto TCP que debemos exponer es el 7051, es el estándar para hacer las llamadas a los chaincodes.
Aunque esta situación es bastante irreal, pues al menos necesitaremos gestionar la autoridad certificadora desde otra ubicación, para poder crear identidades, renovar certificados, etc. Por lo tanto el otro puerto que debemos abrir es el 7054, el puerto TCP estándar del servicio fabric-ca-server.
Para evitar complejidades de red, podemos pensar en una sola red privada con todos los nodos dentro, para que puedan comunicarse sin límites en los puertos que necesiten. Dependiendo del proveedor de cloud elegido, esto puede construirse de una u otra manera.
Pero si queréis conocer los puertos que realmente hacen falta en cada servicio, esta sería la lista completa:
- 7050: Comunicaciones GRPC con el orderer
- 7051: Comunicaciones GRPC con el peer
- 7054: Servicio de gestión de certificados de Fabric-CA-Server
Sobre el servicio DNS hay poco que decir, de momento. Obviamente aprovecharemos el servicio DNS que nos ofrece el proveedor y crearemos una zona externa para poder resolverla desde Internet y quizás una interna, para que los servicios puedan comunicarse entre ellos usando las IPs privadas.
En esta aproximación, todo el software y su configuración debe ser instalado en cada nodo y configurado adecuadamente posteriormente. Esto puede hacerse a mano, siguiendo las instrucciones de Hyperledger Fabric, con alguna herramienta de despliegue específica o con herramienta IAC (Infrastructure as code).
Fase 2: alta disponibilidad
Una vez hemos conseguido un despliegue sencillo: un orderer, una CA y un peer, veamos cómo dar todos estos servicios de una forma continuada en el tiempo.
Nodos peer
El más sencillo de todos los componentes a la hora de conseguir alta disponibilidad es el peer. Los nodos peers son entidades independientes sobre las que instalamos los chaincodes. Durante la instalación de los chaincodes elegimos el canal sobre el que actuarán. Te remito de nuevo a la explicación que te daba sobre qué es un canal en el artículo 1 de la serie.
Si queremos tener los chaincodes en alta disponibilidad, basta con instalar más nodos peers e instalar los chaincodes que necesitemos. Eso sí, debemos tener claro cuántos canales vamos a tener, cuántos chaincodes en cada uno y cuántos peers tendrán esos chaincodes instalados. Es más que aconsejable que los peer estén instalados en zonas de disponibilidad distintas para asegurar la tolerancia a los fallos que puedan producirse en el proveedor.
Distribuir geográficamente los peers puede tener consecuencias en las comunicaciones entre ellos y hacia el resto de elementos, dependiendo de cómo el proveedor cloud implemente el filtrado entre las redes, por lo que de nuevo habrá que vigilar y configurar el filtrado de puertos.
Autoridad certificadora
También podemos hacer un despliegue clásico en alta disponibilidad de la CA si estamos usando fabric-ca-server, del proyecto Hyperledger Fabric
El funcionamiento básico del servicio es mediante una API/REST y con un backend de base de datos donde podemos elegir Postgres o Mysql como motor SQL.
Llevándonos esta arquitectura a la filosofía cloud, tendríamos estos elementos:
- Varios nodos, dos como mínimo, con la herramienta fabric-ca-server instalada
- Backend de base de datos en modo SaaS, o servicio de base de datos gestionado por el cloud.
- Balanceador HTTP/HTTPS para recibir las peticiones API/REST
Este esquema nos da la seguridad de tener el servicio siempre disponible además de liberarnos de las tareas de administración de base de datos al usarlas en modo SaaS.
Servicio de ordering
Y finalmente llegamos al servicio de ordering, sin duda el más importante y complejo dentro de la infraestructura de HyperLedger Fabric.
Los nodos orderers forman un clúster raft entre ellos, y es imprescindible saber cómo funciona un clúster de este tipo para decidir las posibles estrategias de despliegue.
Así que vamos a hacer un breve repaso sobre qué es un clúster raft.
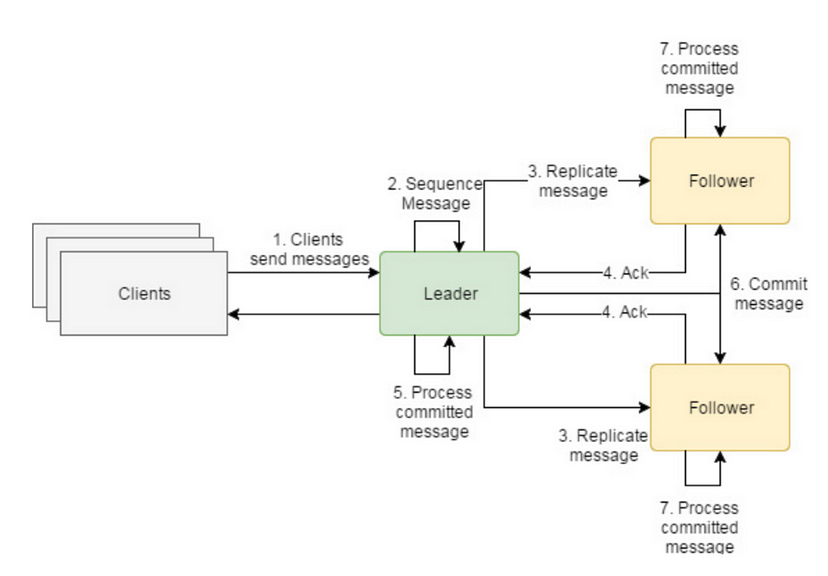
Un clúster raft se encarga de gestionar una máquina de estado distribuida entre todos los nodos, de tal forma que cada uno tenga las mismas transacciones de un estado a otro, mantenidas en un log.
Dentro del clúster existen dos tipos de nodos: leaders y followers. Solo puede haber un leader y el resto son followers. Por supuesto, existe un algoritmo de elección de leader, unos heartbeats para comprobar el estado de leader y resto de nodos y unos timeouts y mecanismos de recuperación ante caídas del leader.
Si quieres profundizar en el funcionamiento del algoritmo de elección de leader, te aconsejo que vayas al artículo de la Wikipedia, o bien a su página oficial.
Cuando el nodo leader recibe un nuevo log, lo replica hacia un número mínimo de nodos, el llamado quorum. El quorum en raft, como en otro tipo de clústers, es (N/2 + 1) es decir, la mitad más uno. Una vez el nuevo log ha sido confirmado por el mínimo de nodos, se puede aplicar a la máquina de estado y seguir admitiendo nodos.
Un log puede contener casi cualquier cosa: datos, inclusión de nuevos nodos, cambios en la configuración, etc.
Un buen esquema de funcionamiento de la replicación es el siguiente, extraído de otro artículo que puede que te interese leer:
Si por alguna circunstancia no hay disponibles un mínimo de nodos que cubra el quórum, el clúster se detiene y deja de procesar operaciones.
Por lo tanto, en un entorno de alta disponibilidad debemos asegurar que al menos tengamos el quórum disponible.
Alta disponibilidad en el quórum del clúster
Veamos algunos ejemplos de configuración:
- Clúster con dos nodos. El quórum sería 2, por lo tanto ambos nodos deben estar siempre funcionando y no tendríamos tolerancia a fallos
- Clúster con tres nodos. El quórum sigue siendo 2, por lo que permitimos el fallo de un nodo. Es una de las configuraciones clásicas en entornos de desarrollo, pero no aconsejable en producción.
- Clúster con 4 nodos. El quórum es 3, por lo que, como en el caso anterior, solo permitimos el fallo de un nodo, y además añadimos un nodo más que no aporta nada
- Clúster con 5 nodos. Tenemos un quórum de 3 y el fallo de dos nodos es posible. Esta es una de las configuraciones clásicas en entornos de producción.
Pero cuando hablamos de entornos en alta disponibilidad, no basta con considerar el fallo de un elemento de computación concreto, debemos ir más allá y contemplar fallos en infraestructuras completas.
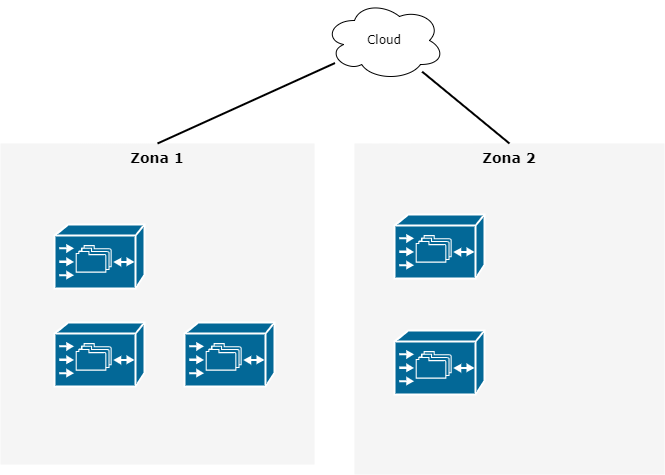
Cuando hacemos despliegues en la nube siempre debemos decidir en cuantas zonas físicas queremos hacer las configuraciones. La decisión típica son 2 zonas geográficas bien separadas para que los posibles eventos que ocurran en una no afecten a la otra. Dependiendo del proveedor de cloud, las zonas pueden o no tener cierta dependencia entre ellas. Siempre tomaremos dos zonas en las que la caída de ambas sea prácticamente imposible.
Configuración de un clúster de 5 nodos en 2 zonas cloud.
La configuración quedaría como se muestra en la imagen.
Como ves, la caída de la zona 1 provocaría la pérdida funcional del clúster.
Por lo tanto, esta configuración no nos sirve en entornos de producción.
Configuración de un clúster de 5 nodos en 3 zonas cloud

Y esta configuración, por fin, es la que soporta la caída de una zona completa perdiendo, como máximo, 2 nodos del clúster y manteniendo vivos los que llegan al quórum.
Organizaciones
Todo el documento hasta aquí ha asumido que solo tenemos una organización en nuestro sistema. Esto significa que cualquier cambio en la configuración de un canal, del servicio de ordering o la firma de una transacción solo debe ser aprobada por esa organización.
Pero, ¿cómo afecta a la alta disponibilidad el hecho de que haya más de una organización?
Hyperledger Fabric muestra sus mejores características cuando intervienen más de una organización tanto en la gestión como en la aportación de infraestructura.
Pero este debate nos dará para un artículo completo y más que interesante, puesto que en él hablaremos del gobierno del dato y la gestión de organizaciones.